一、Spring Boot 入门
1、Spring Boot 简介
简化Spring应用开发的一个框架;
整个Spring技术栈的一个大整合;
J2EE开发的一站式解决方案;
2、微服务
2014,martin fowler
微服务:架构风格(服务微化)
一个应用应该是一组小型服务;可以通过HTTP的方式进行互通;
单体应用:ALL IN ONE
微服务:每一个功能元素最终都是一个可独立替换和独立升级的软件单元;
more >>
欢迎参观我的博客
一、Spring Boot 入门
简化Spring应用开发的一个框架;
整个Spring技术栈的一个大整合;
J2EE开发的一站式解决方案;
2014,martin fowler
微服务:架构风格(服务微化)
一个应用应该是一组小型服务;可以通过HTTP的方式进行互通;
单体应用:ALL IN ONE
微服务:每一个功能元素最终都是一个可独立替换和独立升级的软件单元;
more >>用于求解 Kth Element 问题,也就是第 K 个元素的问题。
可以使用快速排序的 partition() 进行实现。需要先打乱数组,否则最坏情况下时间复杂度为 O(N2)。
用于求解 TopK Elements 问题,也就是 K 个最小元素的问题。使用最小堆来实现 TopK 问题,最小堆使用大顶堆来实现,大顶堆的堆顶元素为当前堆的最大元素。实现过程:不断地往大顶堆中插入新元素,当堆中元素的数量大于 k 时,移除堆顶元素,也就是当前堆中最大的元素,剩下的元素都为当前添加过的元素中最小的 K 个元素。插入和移除堆顶元素的时间复杂度都为 log2N。
堆也可以用于求解 Kth Element 问题,得到了大小为 K 的最小堆之后,因为使用了大顶堆来实现,因此堆顶元素就是第 K 大的元素。
快速选择也可以求解 TopK Elements 问题,因为找到 Kth Element 之后,再遍历一次数组,所有小于等于 Kth Element 的元素都是 TopK Elements。
可以看到,快速选择和堆排序都可以求解 Kth Element 和 TopK Elements 问题。
215. Kth Largest Element in an Array (Medium)
1 | Input: [3,2,1,5,6,4] and k = 2 |
题目描述:找到倒数第 k 个的元素。
排序 :时间复杂度 O(NlogN),空间复杂度 O(1)
1 | public int findKthLargest(int[] nums, int k) { |
堆 :时间复杂度 O(NlogK),空间复杂度 O(K)。
1 | public int findKthLargest(int[] nums, int k) { |
快速选择 :时间复杂度 O(N),空间复杂度 O(1)
1 | public int findKthLargest(int[] nums, int k) { |
347. Top K Frequent Elements (Medium)
1 | Given [1,1,1,2,2,3] and k = 2, return [1,2]. |
设置若干个桶,每个桶存储出现频率相同的数。桶的下标表示数出现的频率,即第 i 个桶中存储的数出现的频率为 i。
把数都放到桶之后,从后向前遍历桶,最先得到的 k 个数就是出现频率最多的的 k 个数。
1 | public int[] topKFrequent(int[] nums, int k) { |
451. Sort Characters By Frequency (Medium)
1 | Input: |
1 | public String frequencySort(String s) { |
荷兰国旗包含三种颜色:红、白、蓝。
有三种颜色的球,算法的目标是将这三种球按颜色顺序正确地排列。它其实是三向切分快速排序的一种变种,在三向切分快速排序中,每次切分都将数组分成三个区间:小于切分元素、等于切分元素、大于切分元素,而该算法是将数组分成三个区间:等于红色、等于白色、等于蓝色。

75. Sort Colors (Medium)
1 | Input: [2,0,2,1,1,0] |
题目描述:只有 0/1/2 三种颜色。
1 | public void sortColors(int[] nums) { |
双指针主要用于遍历数组,两个指针指向不同的元素,从而协同完成任务。
167. Two Sum II - Input array is sorted (Easy)
1 | Input: numbers={2, 7, 11, 15}, target=9 |
题目描述:在有序数组中找出两个数,使它们的和为 target。
使用双指针,一个指针指向值较小的元素,一个指针指向值较大的元素。指向较小元素的指针从头向尾遍历,指向较大元素的指针从尾向头遍历。
数组中的元素最多遍历一次,时间复杂度为 O(N)。只使用了两个额外变量,空间复杂度为 O(1)。
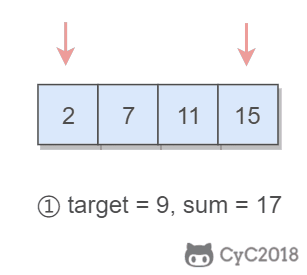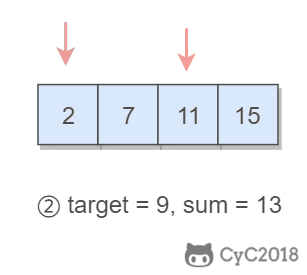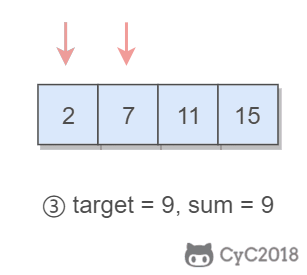
1 | public int[] twoSum(int[] numbers, int target) { |
633. Sum of Square Numbers (Easy)
1 | Input: 5 |
题目描述:判断一个非负整数是否为两个整数的平方和。
可以看成是在元素为 0~target 的有序数组中查找两个数,使得这两个数的平方和为 target,如果能找到,则返回 true,表示 target 是两个整数的平方和。
本题和 167. Two Sum II - Input array is sorted 类似,只有一个明显区别:一个是和为 target,一个是平方和为 target。本题同样可以使用双指针得到两个数,使其平方和为 target。
本题的关键是右指针的初始化,实现剪枝,从而降低时间复杂度。设右指针为 x,左指针固定为 0,为了使 02 + x2 的值尽可能接近 target,我们可以将 x 取为 sqrt(target)。
因为最多只需要遍历一次 0~sqrt(target),所以时间复杂度为 O(sqrt(target))。又因为只使用了两个额外的变量,因此空间复杂度为 O(1)。
1 | public boolean judgeSquareSum(int target) { |
345. Reverse Vowels of a String (Easy)
1 | Given s = "leetcode", return "leotcede". |

使用双指针,一个指针从头向尾遍历,一个指针从尾到头遍历,当两个指针都遍历到元音字符时,交换这两个元音字符。
为了快速判断一个字符是不是元音字符,我们将全部元音字符添加到集合 HashSet 中,从而以 O(1) 的时间复杂度进行该操作。
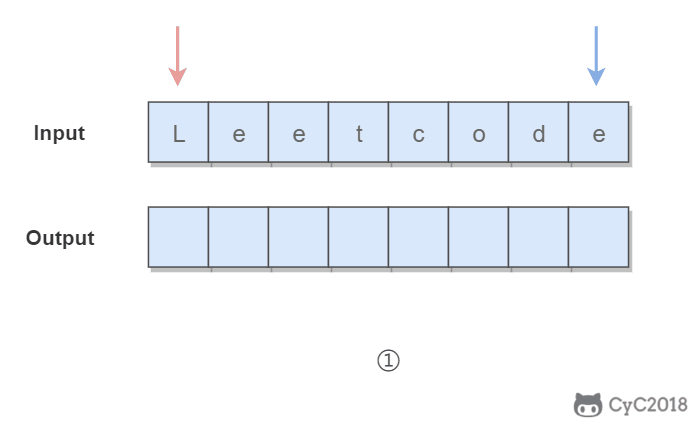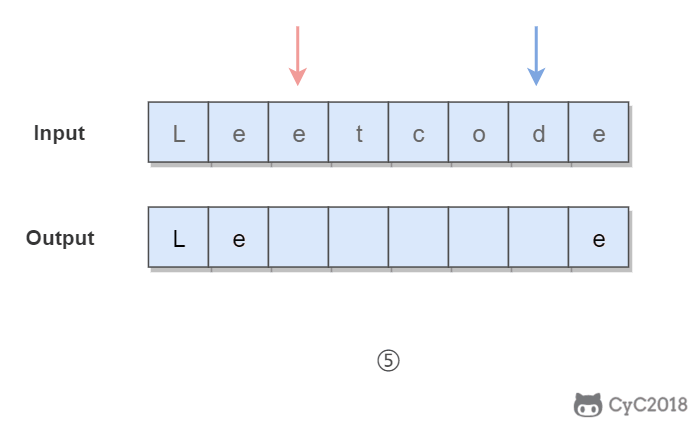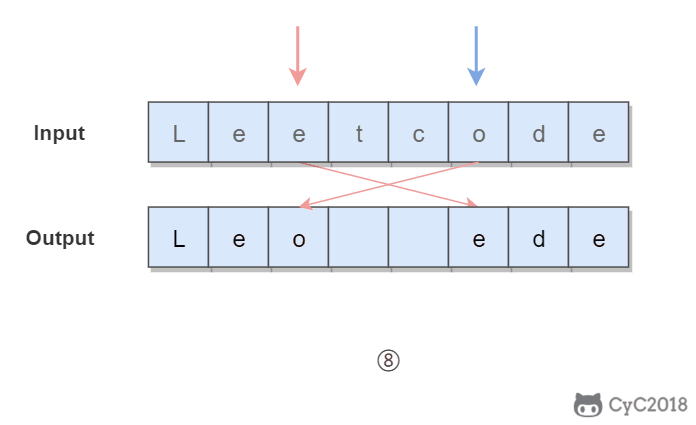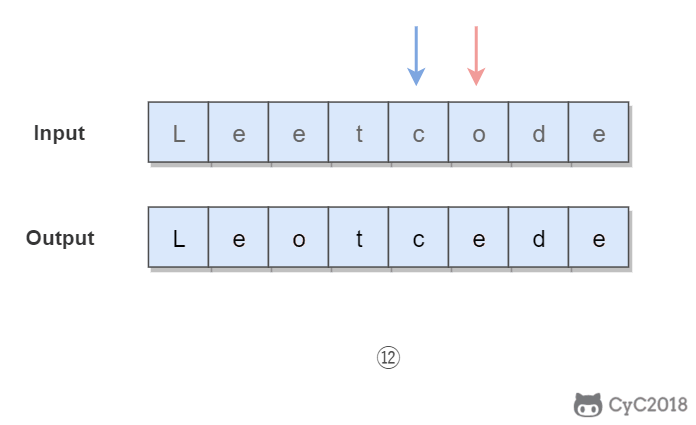
1 | private final static HashSet<Character> vowels = new HashSet<>( |
680. Valid Palindrome II (Easy)
1 | Input: "abca" |
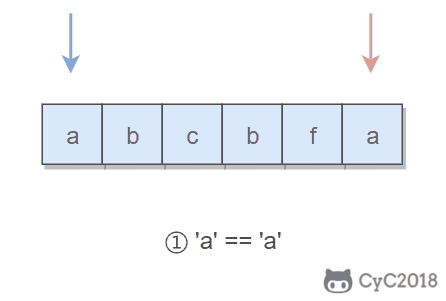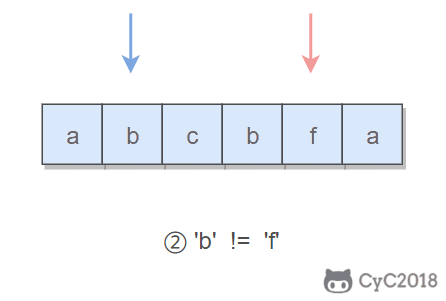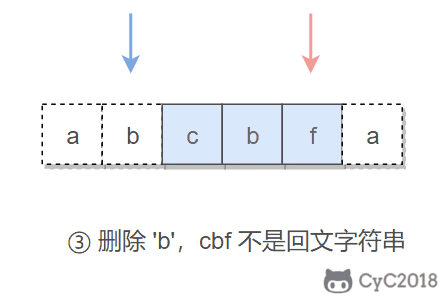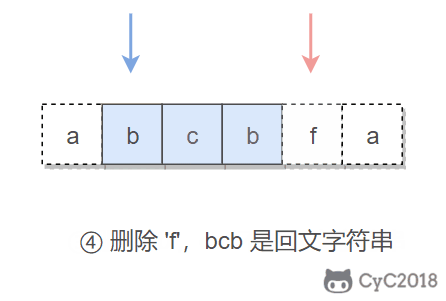
题目描述:可以删除一个字符,判断是否能构成回文字符串。
所谓的回文字符串,是指具有左右对称特点的字符串,例如 “abcba” 就是一个回文字符串。
使用双指针可以很容易判断一个字符串是否是回文字符串:令一个指针从左到右遍历,一个指针从右到左遍历,这两个指针同时移动一个位置,每次都判断两个指针指向的字符是否相同,如果都相同,字符串才是具有左右对称性质的回文字符串。

本题的关键是处理删除一个字符。在使用双指针遍历字符串时,如果出现两个指针指向的字符不相等的情况,我们就试着删除一个字符,再判断删除完之后的字符串是否是回文字符串。
在判断是否为回文字符串时,我们不需要判断整个字符串,因为左指针左边和右指针右边的字符之前已经判断过具有对称性质,所以只需要判断中间的子字符串即可。
在试着删除字符时,我们既可以删除左指针指向的字符,也可以删除右指针指向的字符。
1 | public boolean validPalindrome(String s) { |
88. Merge Sorted Array (Easy)
1 | Input: |
题目描述:把归并结果存到第一个数组上。
需要从尾开始遍历,否则在 nums1 上归并得到的值会覆盖还未进行归并比较的值。
1 | public void merge(int[] nums1, int m, int[] nums2, int n) { |
141. Linked List Cycle (Easy)
使用双指针,一个指针每次移动一个节点,一个指针每次移动两个节点,如果存在环,那么这两个指针一定会相遇。
1 | public boolean hasCycle(ListNode head) { |
524. Longest Word in Dictionary through Deleting (Medium)
1 | Input: |
题目描述:删除 s 中的一些字符,使得它构成字符串列表 d 中的一个字符串,找出能构成的最长字符串。如果有多个相同长度的结果,返回字典序的最小字符串。
通过删除字符串 s 中的一个字符能得到字符串 t,可以认为 t 是 s 的子序列,我们可以使用双指针来判断一个字符串是否为另一个字符串的子序列。
1 | public String findLongestWord(String s, List<String> d) { |
Elasticsearch 是一个实时的分布式搜索分析引擎,解决问题:
1、自动维护数据的分布到多个节点的索引的建立,还有搜索请求分布到多个节点的执行
2、自动维护数据的冗余副本,保证了一旦机器宕机,不会丢失数据
3、封装了更多高级的功能,例如聚合分析的功能,基于地理位置的搜索
more >>一棵树要么是空树,要么有两个指针,每个指针指向一棵树。树是一种递归结构,很多树的问题可以使用递归来处理。
104. Maximum Depth of Binary Tree (Easy)
1 | public int maxDepth(TreeNode root) { |
110. Balanced Binary Tree (Easy)
1 | 3 |
平衡树左右子树高度差都小于等于 1
1 | private boolean result = true; |
543. Diameter of Binary Tree (Easy)
1 | Input: |
1 | private int max = 0; |
226. Invert Binary Tree (Easy)
1 | public TreeNode invertTree(TreeNode root) { |
617. Merge Two Binary Trees (Easy)
1 | Input: |
1 | public TreeNode mergeTrees(TreeNode t1, TreeNode t2) { |
Leetcdoe : 112. Path Sum (Easy)
1 | Given the below binary tree and sum = 22, |
路径和定义为从 root 到 leaf 的所有节点的和。
1 | public boolean hasPathSum(TreeNode root, int sum) { |
437. Path Sum III (Easy)
1 | root = [10,5,-3,3,2,null,11,3,-2,null,1], sum = 8 |
路径不一定以 root 开头,也不一定以 leaf 结尾,但是必须连续。
1 | public int pathSum(TreeNode root, int sum) { |
572. Subtree of Another Tree (Easy)
1 | Given tree s: |
1 | public boolean isSubtree(TreeNode s, TreeNode t) { |
101. Symmetric Tree (Easy)
1 | 1 |
1 | public boolean isSymmetric(TreeNode root) { |
111. Minimum Depth of Binary Tree (Easy)
树的根节点到叶子节点的最小路径长度
1 | public int minDepth(TreeNode root) { |
404. Sum of Left Leaves (Easy)
1 | 3 |
1 | public int sumOfLeftLeaves(TreeNode root) { |
687. Longest Univalue Path (Easy)
1 | 1 |
1 | private int path = 0; |
337. House Robber III (Medium)
1 | 3 |
1 | Map<TreeNode, Integer> cache = new HashMap<>(); |
671. Second Minimum Node In a Binary Tree (Easy)
1 | Input: |
一个节点要么具有 0 个或 2 个子节点,如果有子节点,那么根节点是最小的节点。
1 | public int findSecondMinimumValue(TreeNode root) { |
使用 BFS 进行层次遍历。不需要使用两个队列来分别存储当前层的节点和下一层的节点,因为在开始遍历一层的节点时,当前队列中的节点数就是当前层的节点数,只要控制遍历这么多节点数,就能保证这次遍历的都是当前层的节点。
637. Average of Levels in Binary Tree (Easy)
1 | public List<Double> averageOfLevels(TreeNode root) { |
513. Find Bottom Left Tree Value (Easy)
1 | Input: |
1 | public int findBottomLeftValue(TreeNode root) { |
1 | 1 |
层次遍历使用 BFS 实现,利用的就是 BFS 一层一层遍历的特性;而前序、中序、后序遍历利用了 DFS 实现。
前序、中序、后序遍只是在对节点访问的顺序有一点不同,其它都相同。
① 前序
1 | void dfs(TreeNode root) { |
② 中序
1 | void dfs(TreeNode root) { |
③ 后序
1 | void dfs(TreeNode root) { |
144. Binary Tree Preorder Traversal (Medium)
1 | public List<Integer> preorderTraversal(TreeNode root) { |
145. Binary Tree Postorder Traversal (Medium)
前序遍历为 root -> left -> right,后序遍历为 left -> right -> root。可以修改前序遍历成为 root -> right -> left,那么这个顺序就和后序遍历正好相反。
1 | public List<Integer> postorderTraversal(TreeNode root) { |
94. Binary Tree Inorder Traversal (Medium)
1 | public List<Integer> inorderTraversal(TreeNode root) { |
二叉查找树(BST):根节点大于等于左子树所有节点,小于等于右子树所有节点。
二叉查找树中序遍历有序。
669. Trim a Binary Search Tree (Easy)
1 | Input: |
题目描述:只保留值在 L ~ R 之间的节点
1 | public TreeNode trimBST(TreeNode root, int L, int R) { |
230. Kth Smallest Element in a BST (Medium)
中序遍历解法:
1 | private int cnt = 0; |
递归解法:
1 | public int kthSmallest(TreeNode root, int k) { |
Convert BST to Greater Tree (Easy)
1 | Input: The root of a Binary Search Tree like this: |
先遍历右子树。
1 | private int sum = 0; |
235. Lowest Common Ancestor of a Binary Search Tree (Easy)
1 | _______6______ |
1 | public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { |
236. Lowest Common Ancestor of a Binary Tree (Medium)
1 | _______3______ |
1 | public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { |
108. Convert Sorted Array to Binary Search Tree (Easy)
1 | public TreeNode sortedArrayToBST(int[] nums) { |
109. Convert Sorted List to Binary Search Tree (Medium)
1 | Given the sorted linked list: [-10,-3,0,5,9], |
1 | public TreeNode sortedListToBST(ListNode head) { |
653. Two Sum IV - Input is a BST (Easy)
1 | Input: |
使用中序遍历得到有序数组之后,再利用双指针对数组进行查找。
应该注意到,这一题不能用分别在左右子树两部分来处理这种思想,因为两个待求的节点可能分别在左右子树中。
1 | public boolean findTarget(TreeNode root, int k) { |
530. Minimum Absolute Difference in BST (Easy)
1 | Input: |
利用二叉查找树的中序遍历为有序的性质,计算中序遍历中临近的两个节点之差的绝对值,取最小值。
1 | private int minDiff = Integer.MAX_VALUE; |
501. Find Mode in Binary Search Tree (Easy)
1 | 1 |
答案可能不止一个,也就是有多个值出现的次数一样多。
1 | private int curCnt = 1; |
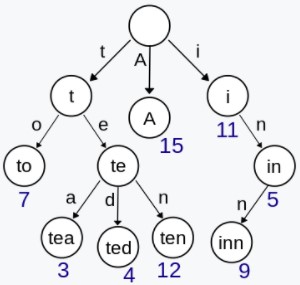
Trie,又称前缀树或字典树,用于判断字符串是否存在或者是否具有某种字符串前缀。
208. Implement Trie (Prefix Tree) (Medium)
1 | class Trie { |
677. Map Sum Pairs (Medium)
1 | Input: insert("apple", 3), Output: Null |
1 | class MapSum { |
283. Move Zeroes (Easy)
1 | For example, given nums = [0, 1, 0, 3, 12], after calling your function, nums should be [1, 3, 12, 0, 0]. |
1 | public void moveZeroes(int[] nums) { |
566. Reshape the Matrix (Easy)
1 | Input: |
1 | public int[][] matrixReshape(int[][] nums, int r, int c) { |
485. Max Consecutive Ones (Easy)
1 | public int findMaxConsecutiveOnes(int[] nums) { |
240. Search a 2D Matrix II (Medium)
1 | [ |
1 | public boolean searchMatrix(int[][] matrix, int target) { |
378. Kth Smallest Element in a Sorted Matrix ((Medium))
1 | matrix = [ |
解题参考:Share my thoughts and Clean Java Code
二分查找解法:
1 | public int kthSmallest(int[][] matrix, int k) { |
堆解法:
1 | public int kthSmallest(int[][] matrix, int k) { |
645. Set Mismatch (Easy)
1 | Input: nums = [1,2,2,4] |
1 | Input: nums = [1,2,2,4] |
最直接的方法是先对数组进行排序,这种方法时间复杂度为 O(NlogN)。本题可以以 O(N) 的时间复杂度、O(1) 空间复杂度来求解。
主要思想是通过交换数组元素,使得数组上的元素在正确的位置上。
1 | public int[] findErrorNums(int[] nums) { |
287. Find the Duplicate Number (Medium)
要求不能修改数组,也不能使用额外的空间。
二分查找解法:
1 | public int findDuplicate(int[] nums) { |
双指针解法,类似于有环链表中找出环的入口:
1 | public int findDuplicate(int[] nums) { |
667. Beautiful Arrangement II (Medium)
1 | Input: n = 3, k = 2 |
题目描述:数组元素为 1~n 的整数,要求构建数组,使得相邻元素的差值不相同的个数为 k。
让前 k+1 个元素构建出 k 个不相同的差值,序列为:1 k+1 2 k 3 k-1 … k/2 k/2+1.
1 | public int[] constructArray(int n, int k) { |
697. Degree of an Array (Easy)
1 | Input: [1,2,2,3,1,4,2] |
题目描述:数组的度定义为元素出现的最高频率,例如上面的数组度为 3。要求找到一个最小的子数组,这个子数组的度和原数组一样。
1 | public int findShortestSubArray(int[] nums) { |
766. Toeplitz Matrix (Easy)
1 | 1234 |
1 | public boolean isToeplitzMatrix(int[][] matrix) { |
565. Array Nesting (Medium)
1 | Input: A = [5,4,0,3,1,6,2] |
题目描述:S[i] 表示一个集合,集合的第一个元素是 A[i],第二个元素是 A[A[i]],如此嵌套下去。求最大的 S[i]。
1 | public int arrayNesting(int[] nums) { |
769. Max Chunks To Make Sorted (Medium)
1 | Input: arr = [1,0,2,3,4] |
题目描述:分隔数组,使得对每部分排序后数组就为有序。
1 | public int maxChunksToSorted(int[] arr) { |
链表是空节点,或者有一个值和一个指向下一个链表的指针,因此很多链表问题可以用递归来处理。
160. Intersection of Two Linked Lists (Easy)
例如以下示例中 A 和 B 两个链表相交于 c1:
1 | A: a1 → a2 |
但是不会出现以下相交的情况,因为每个节点只有一个 next 指针,也就只能有一个后继节点,而以下示例中节点 c 有两个后继节点。
1 | A: a1 → a2 d1 → d2 |
要求时间复杂度为 O(N),空间复杂度为 O(1)。如果不存在交点则返回 null。
设 A 的长度为 a + c,B 的长度为 b + c,其中 c 为尾部公共部分长度,可知 a + c + b = b + c + a。
当访问 A 链表的指针访问到链表尾部时,令它从链表 B 的头部开始访问链表 B;同样地,当访问 B 链表的指针访问到链表尾部时,令它从链表 A 的头部开始访问链表 A。这样就能控制访问 A 和 B 两个链表的指针能同时访问到交点。
如果不存在交点,那么 a + b = b + a,以下实现代码中 l1 和 l2 会同时为 null,从而退出循环。
1 | public ListNode getIntersectionNode(ListNode headA, ListNode headB) { |
如果只是判断是否存在交点,那么就是另一个问题,即 编程之美 3.6 的问题。有两种解法:
206. Reverse Linked List (Easy)
递归
1 | public ListNode reverseList(ListNode head) { |
头插法
1 | public ListNode reverseList(ListNode head) { |
21. Merge Two Sorted Lists (Easy)
1 | public ListNode mergeTwoLists(ListNode l1, ListNode l2) { |
83. Remove Duplicates from Sorted List (Easy)
1 | Given 1->1->2, return 1->2. |
1 | public ListNode deleteDuplicates(ListNode head) { |
19. Remove Nth Node From End of List (Medium)
1 | Given linked list: 1->2->3->4->5, and n = 2. |
1 | public ListNode removeNthFromEnd(ListNode head, int n) { |
24. Swap Nodes in Pairs (Medium)
1 | Given 1->2->3->4, you should return the list as 2->1->4->3. |
题目要求:不能修改结点的 val 值,O(1) 空间复杂度。
1 | public ListNode swapPairs(ListNode head) { |
445. Add Two Numbers II (Medium)
1 | Input: (7 -> 2 -> 4 -> 3) + (5 -> 6 -> 4) |
题目要求:不能修改原始链表。
1 | public ListNode addTwoNumbers(ListNode l1, ListNode l2) { |
234. Palindrome Linked List (Easy)
题目要求:以 O(1) 的空间复杂度来求解。
切成两半,把后半段反转,然后比较两半是否相等。
1 | public boolean isPalindrome(ListNode head) { |
725. Split Linked List in Parts(Medium)
1 | Input: |
题目描述:把链表分隔成 k 部分,每部分的长度都应该尽可能相同,排在前面的长度应该大于等于后面的。
1 | public ListNode[] splitListToParts(ListNode root, int k) { |
328. Odd Even Linked List (Medium)
1 | Example: |
1 | public ListNode oddEvenList(ListNode head) { |
241. Different Ways to Add Parentheses (Medium)
1 | Input: "2-1-1". |
1 | public List<Integer> diffWaysToCompute(String input) { |
95. Unique Binary Search Trees II (Medium)
给定一个数字 n,要求生成所有值为 1…n 的二叉搜索树。
1 | Input: 3 |
1 | public List<TreeNode> generateTrees(int n) { |
哈希表使用 O(N) 空间复杂度存储数据,并且以 O(1) 时间复杂度求解问题。
Java 中的 HashSet 用于存储一个集合,可以查找元素是否在集合中。如果元素有穷,并且范围不大,那么可以用一个布尔数组来存储一个元素是否存在。例如对于只有小写字符的元素,就可以用一个长度为 26 的布尔数组来存储一个字符集合,使得空间复杂度降低为 O(1)。
Java 中的 HashMap 主要用于映射关系,从而把两个元素联系起来。HashMap 也可以用来对元素进行计数统计,此时键为元素,值为计数。和 HashSet 类似,如果元素有穷并且范围不大,可以用整型数组来进行统计。在对一个内容进行压缩或者其它转换时,利用 HashMap 可以把原始内容和转换后的内容联系起来。例如在一个简化 url 的系统中 [Leetcdoe : 535. Encode and Decode TinyURL (Medium)
Leetcode,利用 HashMap 就可以存储精简后的 url 到原始 url 的映射,使得不仅可以显示简化的 url,也可以根据简化的 url 得到原始 url 从而定位到正确的资源�) / 力扣,利用 HashMap 就可以存储精简后的 url 到原始 url 的映射,使得不仅可以显示简化的 url,也可以根据简化的 url 得到原始 url 从而定位到正确的资源�)
1. Two Sum (Easy)
可以先对数组进行排序,然后使用双指针方法或者二分查找方法。这样做的时间复杂度为 O(NlogN),空间复杂度为 O(1)。
用 HashMap 存储数组元素和索引的映射,在访问到 nums[i] 时,判断 HashMap 中是否存在 target - nums[i],如果存在说明 target - nums[i] 所在的索引和 i 就是要找的两个数。该方法的时间复杂度为 O(N),空间复杂度为 O(N),使用空间来换取时间。
1 | public int[] twoSum(int[] nums, int target) { |
217. Contains Duplicate (Easy)
1 | public boolean containsDuplicate(int[] nums) { |
594. Longest Harmonious Subsequence (Easy)
1 | Input: [1,3,2,2,5,2,3,7] |
和谐序列中最大数和最小数之差正好为 1,应该注意的是序列的元素不一定是数组的连续元素。
1 | public int findLHS(int[] nums) { |
128. Longest Consecutive Sequence (Hard)
1 | Given [100, 4, 200, 1, 3, 2], |
要求以 O(N) 的时间复杂度求解。
1 | public int longestConsecutive(int[] nums) { |
正常实现
1 | Input : [1,2,3,4,5] |
1 | public int binarySearch(int[] nums, int key) { |
时间复杂度
二分查找也称为折半查找,每次都能将查找区间减半,这种折半特性的算法时间复杂度为 O(logN)。
m 计算
有两种计算中值 m 的方式:
l + h 可能出现加法溢出,也就是说加法的结果大于整型能够表示的范围。但是 l 和 h 都为正数,因此 h - l 不会出现加法溢出问题。所以,最好使用第二种计算法方法。
未成功查找的返回值
循环退出时如果仍然没有查找到 key,那么表示查找失败。可以有两种返回值:
变种
二分查找可以有很多变种,实现变种要注意边界值的判断。例如在一个有重复元素的数组中查找 key 的最左位置的实现如下:
1 | public int binarySearch(int[] nums, int key) { |
该实现和正常实现有以下不同:
在 nums[m] >= key 的情况下,可以推导出最左 key 位于 [l, m] 区间中,这是一个闭区间。h 的赋值表达式为 h = m,因为 m 位置也可能是解。
在 h 的赋值表达式为 h = m 的情况下,如果循环条件为 l <= h,那么会出现循环无法退出的情况,因此循环条件只能是 l < h。以下演示了循环条件为 l <= h 时循环无法退出的情况:
1 | nums = {0, 1, 2}, key = 1 |
当循环体退出时,不表示没有查找到 key,因此最后返回的结果不应该为 -1。为了验证有没有查找到,需要在调用端判断一下返回位置上的值和 key 是否相等。
69. Sqrt(x) (Easy)
1 | Input: 4 |
一个数 x 的开方 sqrt 一定在 0 ~ x 之间,并且满足 sqrt == x / sqrt。可以利用二分查找在 0 ~ x 之间查找 sqrt。
对于 x = 8,它的开方是 2.82842…,最后应该返回 2 而不是 3。在循环条件为 l <= h 并且循环退出时,h 总是比 l 小 1,也就是说 h = 2,l = 3,因此最后的返回值应该为 h 而不是 l。
1 | public int mySqrt(int x) { |
744. Find Smallest Letter Greater Than Target (Easy)
1 | Input: |
题目描述:给定一个有序的字符数组 letters 和一个字符 target,要求找出 letters 中大于 target 的最小字符,如果找不到就返回第 1 个字符。
1 | public char nextGreatestLetter(char[] letters, char target) { |
540. Single Element in a Sorted Array (Medium)
1 | Input: [1, 1, 2, 3, 3, 4, 4, 8, 8] |
题目描述:一个有序数组只有一个数不出现两次,找出这个数。
要求以 O(logN) 时间复杂度进行求解,因此不能遍历数组并进行异或操作来求解,这么做的时间复杂度为 O(N)。
令 index 为 Single Element 在数组中的位置。在 index 之后,数组中原来存在的成对状态被改变。如果 m 为偶数,并且 m + 1 < index,那么 nums[m] == nums[m + 1];m + 1 >= index,那么 nums[m] != nums[m + 1]。
从上面的规律可以知道,如果 nums[m] == nums[m + 1],那么 index 所在的数组位置为 [m + 2, h],此时令 l = m + 2;如果 nums[m] != nums[m + 1],那么 index 所在的数组位置为 [l, m],此时令 h = m。
因为 h 的赋值表达式为 h = m,那么循环条件也就只能使用 l < h 这种形式。
1 | public int singleNonDuplicate(int[] nums) { |
278. First Bad Version (Easy)
题目描述:给定一个元素 n 代表有 [1, 2, …, n] 版本,在第 x 位置开始出现错误版本,导致后面的版本都错误。可以调用 isBadVersion(int x) 知道某个版本是否错误,要求找到第一个错误的版本。
如果第 m 个版本出错,则表示第一个错误的版本在 [l, m] 之间,令 h = m;否则第一个错误的版本在 [m + 1, h] 之间,令 l = m + 1。
因为 h 的赋值表达式为 h = m,因此循环条件为 l < h。
1 | public int firstBadVersion(int n) { |
153. Find Minimum in Rotated Sorted Array (Medium)
1 | Input: [3,4,5,1,2], |
1 | public int findMin(int[] nums) { |
34. Find First and Last Position of Element in Sorted Array
1 | Input: nums = [5,7,7,8,8,10], target = 8 |
题目描述:给定一个有序数组 nums 和一个目标 target,要求找到 target 在 nums 中的第一个位置和最后一个位置。
可以用二分查找找出第一个位置和最后一个位置,但是寻找的方法有所不同,需要实现两个二分查找。我们将寻找 target 最后一个位置,转换成寻找 target+1 第一个位置,再往前移动一个位置。这样我们只需要实现一个二分查找代码即可。
1 | public int[] searchRange(int[] nums, int target) { |
在寻找第一个位置的二分查找代码中,需要注意 h 的取值为 nums.length,而不是 nums.length - 1。先看以下示例:
1 | nums = [2,2], target = 2 |
如果 h 的取值为 nums.length - 1,那么 last = findFirst(nums, target + 1) - 1 = 1 - 1 = 0。这是因为 findLeft 只会返回 [0, nums.length - 1] 范围的值,对于 findFirst([2,2], 3) ,我们希望返回 3 插入 nums 中的位置,也就是数组最后一个位置再往后一个位置,即 nums.length。所以我们需要将 h 取值为 nums.length,从而使得 findFirst返回的区间更大,能够覆盖 target 大于 nums 最后一个元素的情况。
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia-plus根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true